Cassandra consistency
Distributed databases became increasingly popular for applications that needs scale. In game development this is one of the requirements, if an online game hits global market you need a database that can handle a big load of users from around the globe.
And casssandra can do that, it's a distributed NoSQL database, which means that it doesn't follow SQL standard, comes with its own query language and unique way of storing data. It is designed to handle large amounts of data across many servers and data centers, providing high availability without a single point of failure.
Cassandra node
Cassandra node is an instance of cassandra database. It's an installation of a database. A node can be on a
- virtual machine
- container
- bare metal
Partition vs replica
It's important to understand that one cassandra node does not necessary contain all the database data. This ultimately depends on the settings and number of total nodes. Each node contains partition of data, that can be up to 100%.
In a single node scenario, the node contains 100% of the data. In a multi-node scenario each node contains for example 10% of the whole data.
Another important point is that a node can contain a replica of other partitions. One example would be having 10 nodes, each node contains 10% of data and also each node contains replication of 2 other nodes.
In a single node scenario, the node contains 100% of the data. In a multi-node scenario each node contains for example 10% of the whole data.
Another important point is that a node can contain a replica of other partitions. One example would be having 10 nodes, each node contains 10% of data and also each node contains replication of 2 other nodes.
Data distribution
Let's look closer on how the data are distributed across the nodes. Imagine 6 nodes database cluster with no replication. The whole database is split into partitions A, B, C, D, E, F, where each node contains exactly one partition.
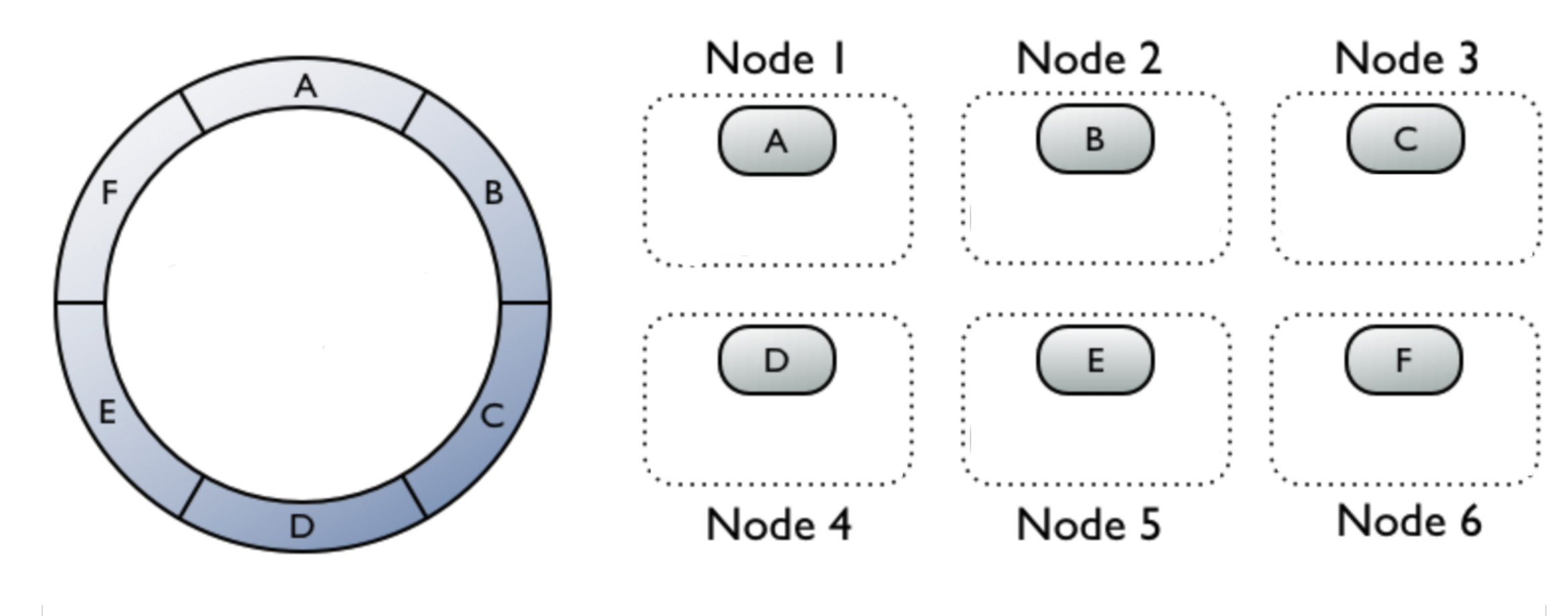 Now let's have a simple table called Users with primary key user_id. The primary key is in cassandra world called a partition key.
Now let's have a simple table called Users with primary key user_id. The primary key is in cassandra world called a partition key.
During the insert cassandra calculates partition by hashing the primary key and finding the right partition range.
Example in 6 node cluster
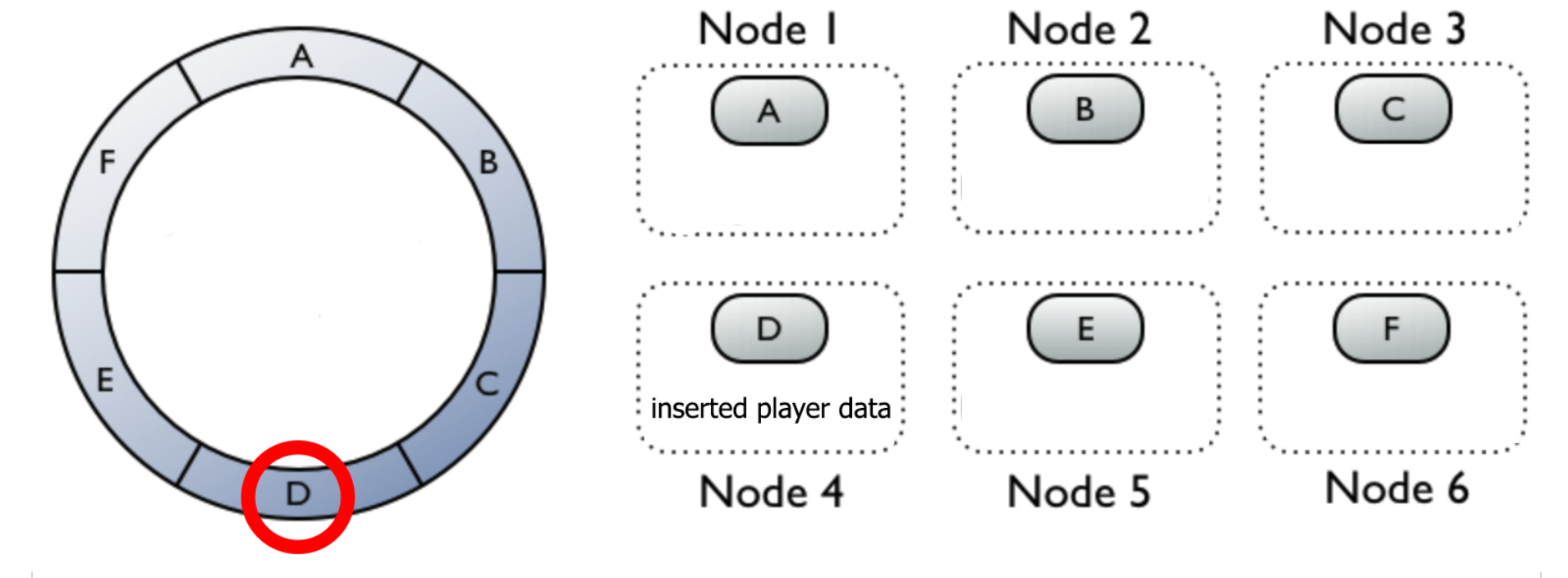
 Inserting data into a partition D (node 4) will trigger insert into other two neighbouring nodes (5 and 6).
Inserting data into a partition D (node 4) will trigger insert into other two neighbouring nodes (5 and 6).
Strong consistency means all the data upon read/write are up to date. Once the query has successfully responded there is a strong guarantee that the data are the most up to date.
On the other hand if a client decide for lower consistency level, the guarantee is not there. Client can get recent data or it can get older data, same applies for writes. The data will get updated eventually, depends on number of nodes, network speed and other factors.
Consistency level is based on a number of nodes that are required to respond. Level one consistency would require only one of the node to respond before returning back to client. Level all would require all of them.
Consistency levels
Quorum represents minimum number of nodes that will assure strong consistency. Use this level if you require strongly consistent data and the best possible performance.
The choosing of the right level is a trade-off between consistency and performance. Eventually consistent query will perform faster than strongly consistent one, but you are in risk of getting older data. If you don't care about the most recent data it's perfectly fine to use lower consistency level. If the consistent data is something your application require you should go with quorum or higher.
Here's interesting to see that with low level of consistency the client does not always get what it expect when inserting and immediate reading of specific rows. However the level of inconsistent reads is still very low compare to total number of queries performed.
Now let's have a simple table called Users with primary key user_id. The primary key is in cassandra world called a partition key.
CREATE TABLE IF NOT EXISTS Users (user_id UUID PRIMARY KEY, <...other fields...>); INSERT INTO Users (user_id, ....) VALUES (?,...)
During the insert cassandra calculates partition by hashing the primary key and finding the right partition range.
partition = hash(primary_key) modulo number_of_partition
Example in 6 node cluster
hash(user_id) = 12345 partition = 12345 mod 6 = 3 data partition is D (node 4)
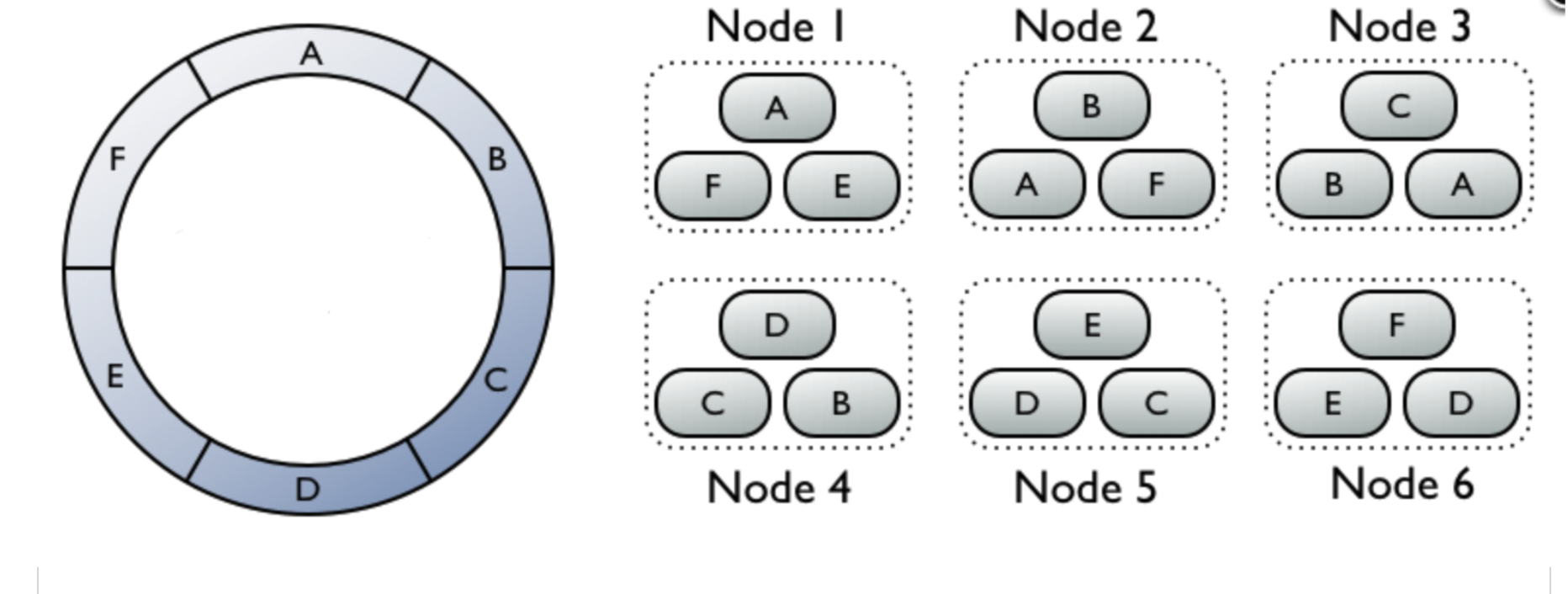
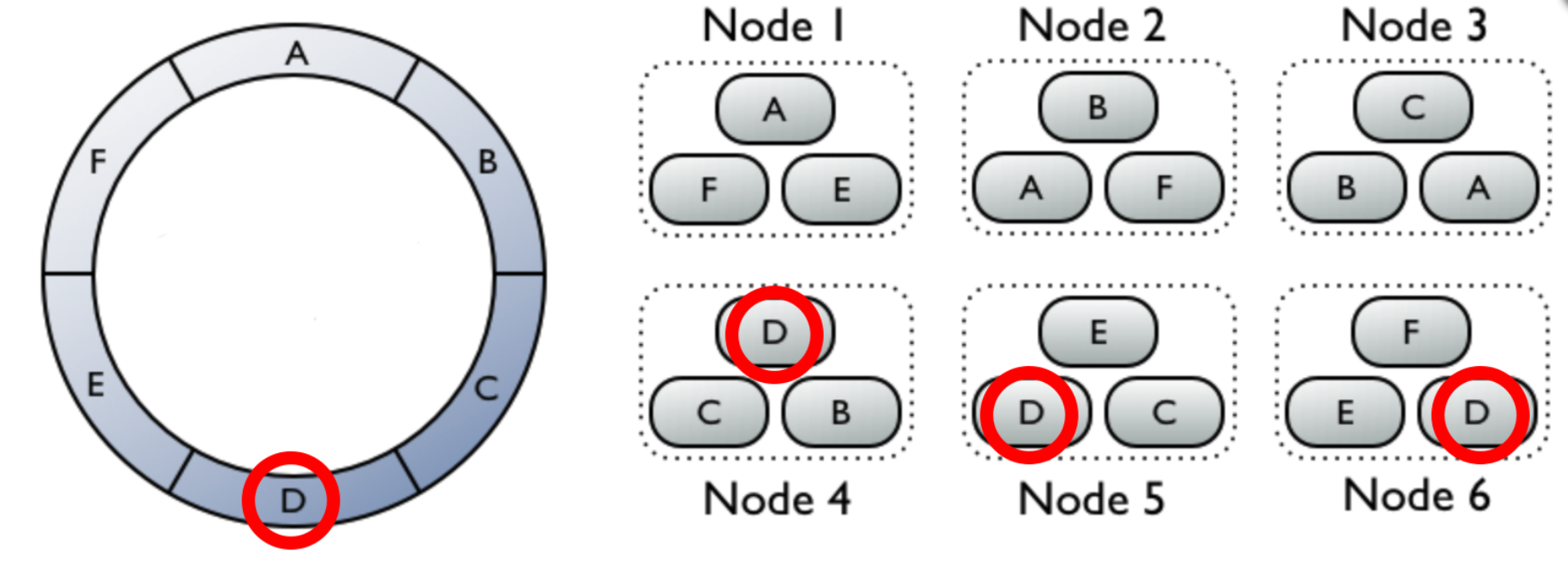
Data replication
Data can be replicated to ensure reliability and fault tolerance. The replication is based on replication factor that can be in range from 1 to total number of nodes. Let's go back to our 6 cluster example, but this time each node will contain exactly 3 partitions. 1 regular partition and 2 replicas of other partitions.
Inserting data into a partition D (node 4) will trigger insert into other two neighbouring nodes (5 and 6).
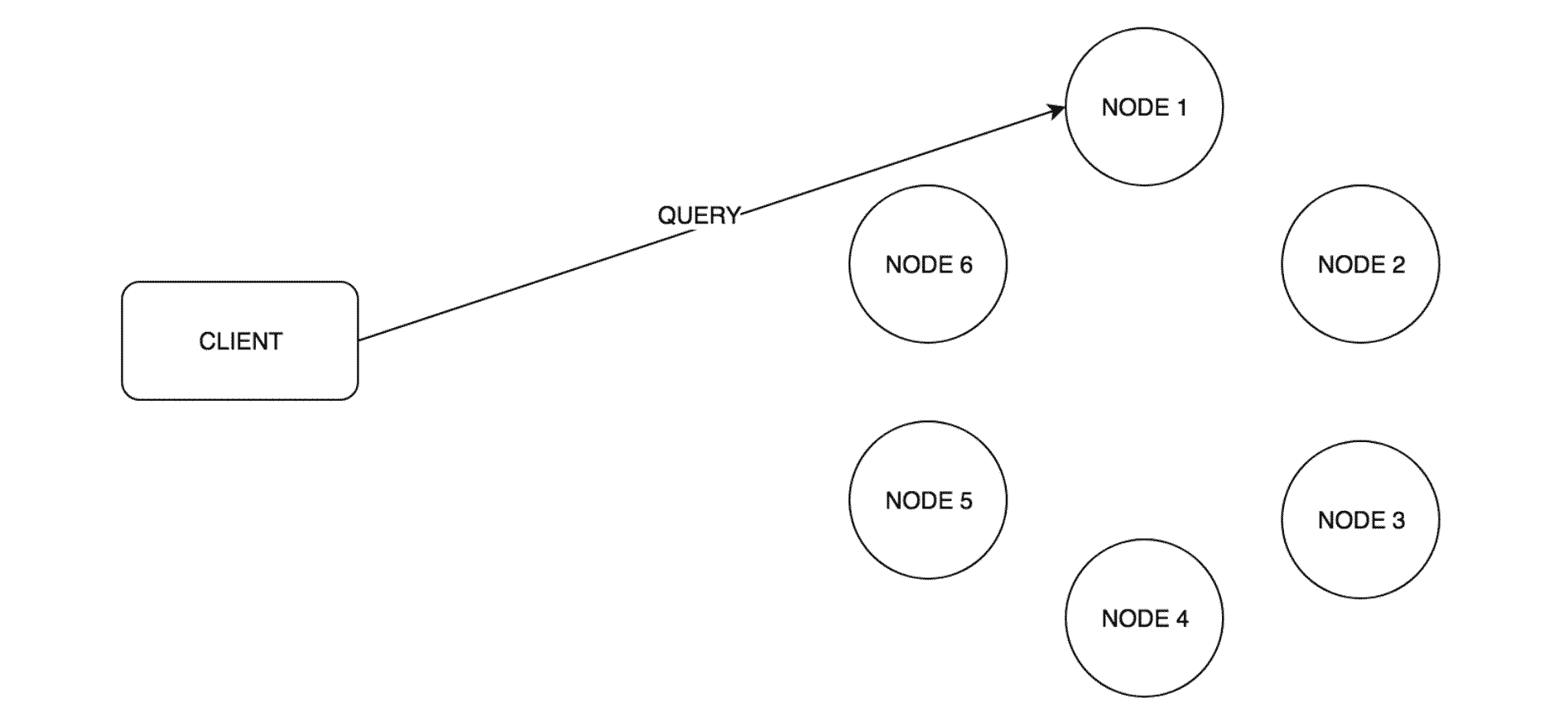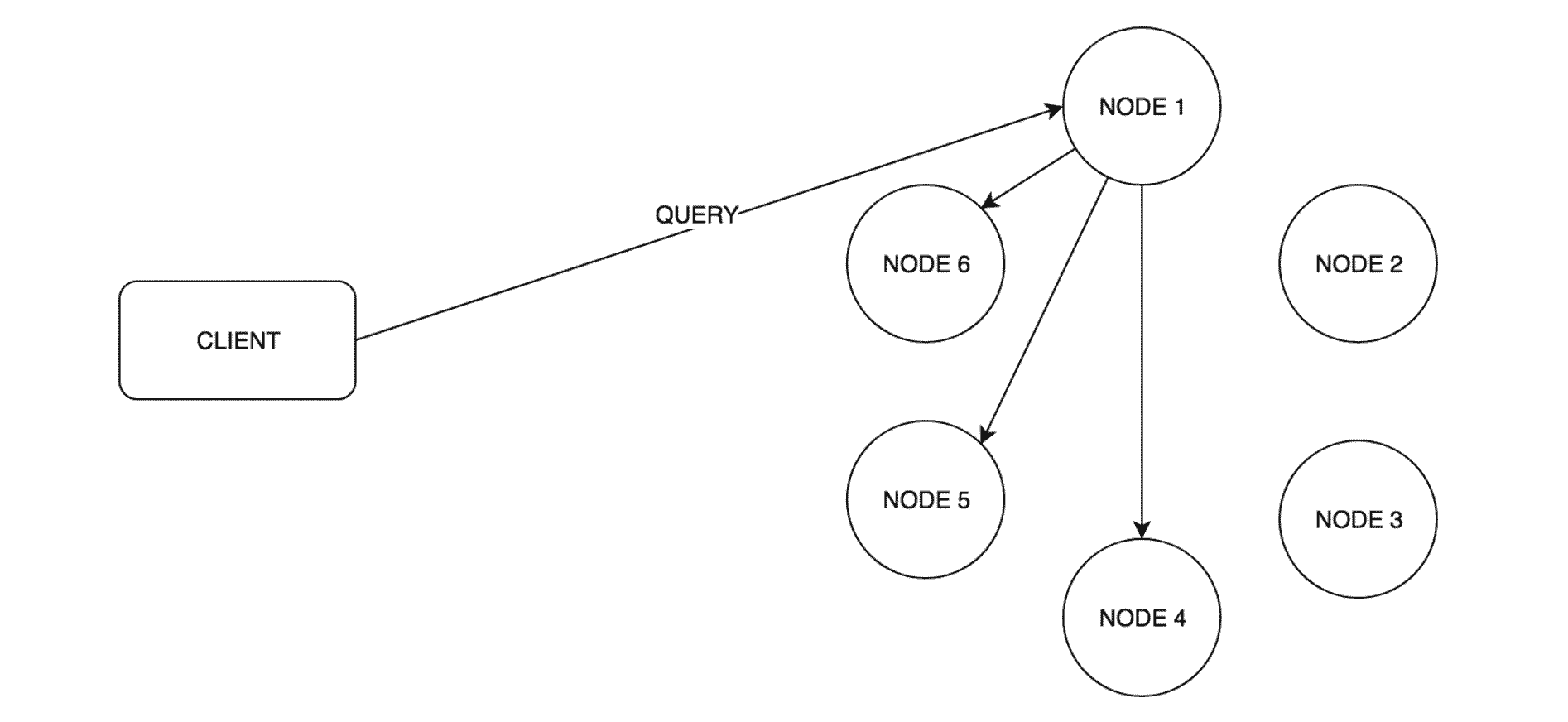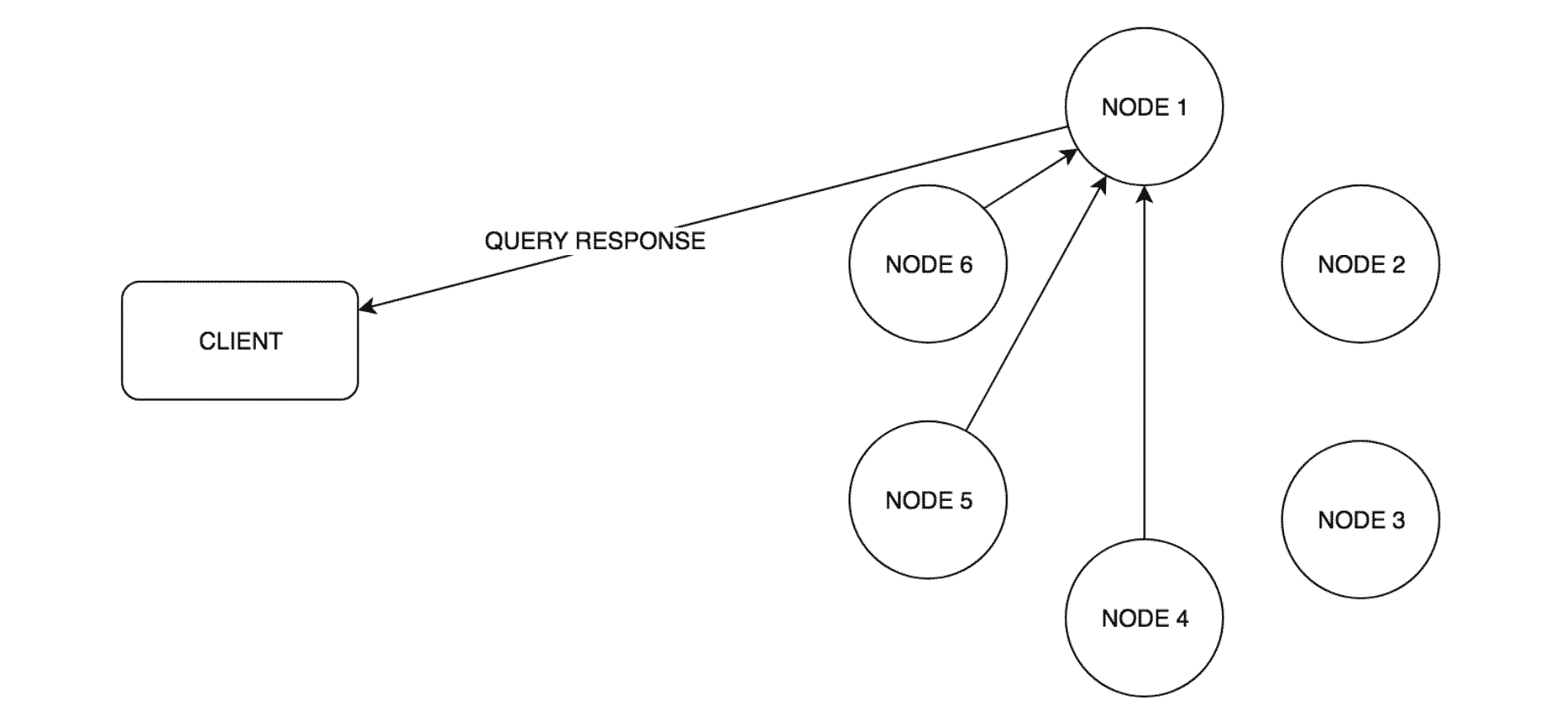
Query request flow
Here's a complete flow of query request:
- Client sends query request
- One of the Cassandra nodes is selected as a coordinator
- Coordinator calculates the hash to select the partition and nodes it belongs to
- Coordinator sends query request to all nodes that are responsible for the partitions
- Responsible nodes replies with success/failed response
- Coordinator replies back to client
Consistency
Now with all that said above we can now show how the consistency in Cassandra actually works. Cassandra comes with something called tunable consistency. A client can set a level of consistency per query and decide whether the data are strongly consistent or eventually consistent.Strong consistency means all the data upon read/write are up to date. Once the query has successfully responded there is a strong guarantee that the data are the most up to date.
On the other hand if a client decide for lower consistency level, the guarantee is not there. Client can get recent data or it can get older data, same applies for writes. The data will get updated eventually, depends on number of nodes, network speed and other factors.
Consistency level is based on a number of nodes that are required to respond. Level one consistency would require only one of the node to respond before returning back to client. Level all would require all of them.
Consistency levels
- One
- Two
- Three
- All
- Quorum
Quorum represents minimum number of nodes that will assure strong consistency. Use this level if you require strongly consistent data and the best possible performance.
The choosing of the right level is a trade-off between consistency and performance. Eventually consistent query will perform faster than strongly consistent one, but you are in risk of getting older data. If you don't care about the most recent data it's perfectly fine to use lower consistency level. If the consistent data is something your application require you should go with quorum or higher.
Test
I made a simple test to see how the database behave with different levels of consistency. The test was done on a 3 nodes cluster database.| Consistency level | Insert 100k rows | Select 100k rows | Insert and selecting 100k rows |
|---|---|---|---|
| ONE | 73 [s] | 74 [s] | 149 [s], 63 failed reads |
| TWO | 118 [s] | 122 [s] | 241 [s] |
| THREE | 155 [s] | 160 [s] | 317 [s] |
| QUORUM | 118 [s] | 123 [s] | 242 [s] |
| QUORUM, 1 node offline | 165 [s] | 167 [s] | 338 [s] |
| QUORUM, 2 nodes offline | Error: Not enough replicas available | Error: Not enough replicas available | Error: Not enough replicas available |
Here's interesting to see that with low level of consistency the client does not always get what it expect when inserting and immediate reading of specific rows. However the level of inconsistent reads is still very low compare to total number of queries performed.